In this article, we will simplify a commonly seen Google-indexing problem: “Duplicate, Google chose different canonical than user.”
In simple terms, this status means that Google didn’t agree with your canonical hints and chose a different page to the canonical version. As a result, the page is not in Google’s index.
| Canonical proposed by the website | Page selected by Google as canonical | |
| Page A | Page B | Page C |
There are three common reasons for this status, two of them are less obvious for most SEOs, yet they occur quite frequently.
How to navigate “Duplicate, Google chose different canonical than user”
First, I will show you some basics on how to navigate the report, how to check the number of affected pages, as well as how to check a sample of the affected pages.
Then we will discuss how to fix this indexing problem.
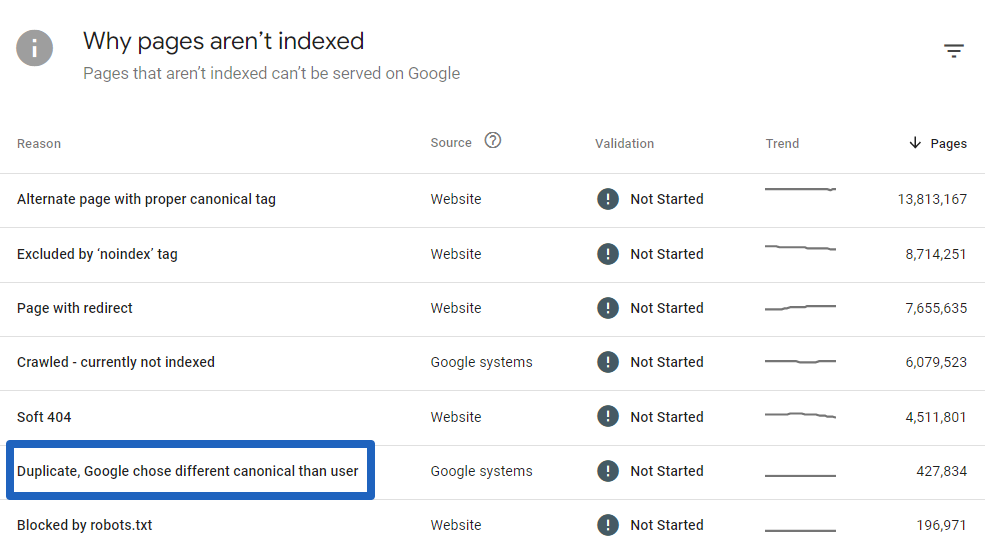
Finding Out How Many Pages Are Affected
First, you need to find out how many pages are affected. To do this, go to Google Search Console and click on Indexing -> Pages.
In this case, almost half a million pages are affected:
Looking at Examples of Affected Pages
When you click on “Duplicate, Google chose different canonical than user”, you can view a sample of affected pages (up to 1k URLs).
Figuring Out Which Pages Google Chose as the Canonical One
To figure out which page Google thinks is the canonical one, you need to use the “Inspect URL” feature.
To do this, hover over the URL and click on the icon of the magnifying glass.
Then you will get information that a page is not on Google:
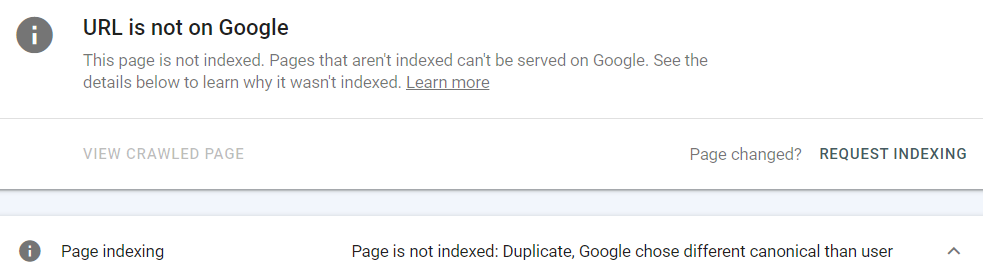
Finally, scroll down to the ‘Page indexing’ section to see which URL Google treats as the main one.

How to handle pages classified as “Duplicate Google choose different canonical”
Once you’ve figured out which page Google considers to be the main one, compare it to your chosen page.

Case 1: The Pages Look Similar
If the pages look pretty much the same, it makes sense that Google chose one of them as a duplicate; Google tries to keep its index clean and simple.
If you want both pages to show up in Google, you will need to make them clearly different.
Case 2: The Pages Don’t Look Similar
Sometimes, Google gets it wrong and thinks two totally different pages are duplicates.
For example, as I explained in the article: “Google’s duplicate content detection is wrong”, Google once thought that e-commerce pages offering an iPhone and a JBL speaker were the same.

So why is it even possible that Google might classify two totally unrelated pages as duplicates?
This could be due to:
- A Google bug: Like any software, Google can have glitches.
- Problems with JavaScript: Google sometimes struggles to fully understand JavaScript code. As a result, it may not be able to see content generated by JavaScript.
- Patterns of duplicate content: Google might think it’s seeing a pattern of duplicate content on your site. Then, it may classify a page as a duplicate even without visiting it(!)
The Problem Might Be JavaScript
Gary Illyes from Google has warned that websites using a lot of JavaScript might run into duplicate-content issues.
As Gary explained, in the case of JavaScript-heavy websites, Google can’t usually render a JavaScript website properly.
As a result, Google won’t see any content – that can obviously make Google think these pages are in fact duplicates.
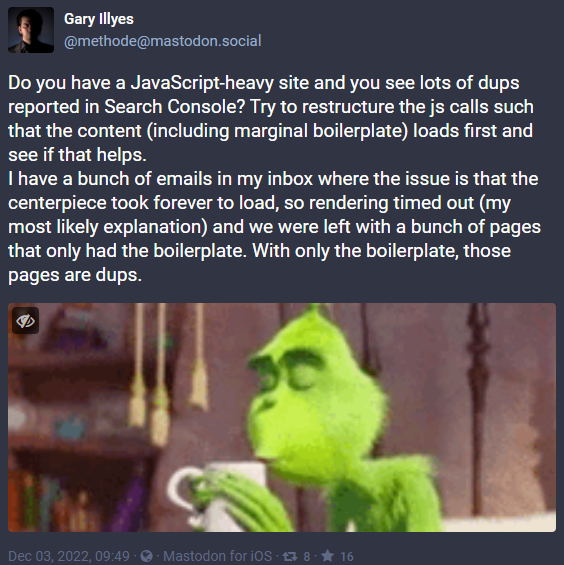
This issue with JavaScript can cause other problems too, like ranking issues and problems with “soft 404” errors.
As part of every audit, you need to make sure that Google can correctly understand your JavaScript content. Shortly we will publish an about how to audit JavaScript SEO so stay tuned!
Patterns of Duplicate Content
We’ve already talked about two possible reasons for duplicate content: problems with JavaScript and pages that look too similar.
But there’s another possible reason: Google’s predictive approach.
As John Mueller from Google explains:
- “What tends to happen on our side is we have multiple levels of trying to understand when there is duplicate content on a site. (…) The other thing is kind of a broader predictive approach that we have where we look at the URL structure of a website where we see, well, in the past, when we’ve looked at URLs that look like this, we’ve seen they have the same content as URLs like this. And then we’ll essentially learn that pattern and say, URLs that look like this are the same as URLs that look like this.”
Fixing duplicate-content issues caused by Google’s pattern learning is a bit more complicated and depends on your website and its URL pattern. If you think this is happening to your website, reach out to us.
Wrapping up
“Discovered – currently not indexed” can cause serious damage to the visibility of your business in Google, especially when Google makes a mistake by wrongly classifying a page as duplicate content.
You should regularly check Google Search Console to see which pages are affected by this very issue. Knowing which pages are affected is the first step to solving the indexing issues.