
Google recently changed something in its deduplication systems. And from what I’m seeing, that change was a mistake.
In October, I started seeing multiple client websites reporting an increased number of “Duplicate, Google chose different canonical than user” pages.
I know it’s not because these websites made significant changes on their end — they are our clients at Onely. It must have been a change in how Google chooses the canonical URL when presented with multiple variants.
Why did I say this isn’t a positive change? See for yourself:

Unfortunately, I can’t share any specific pages for these websites. But just looking at the URL path, you can see that Google made a mistake. These are not the same:

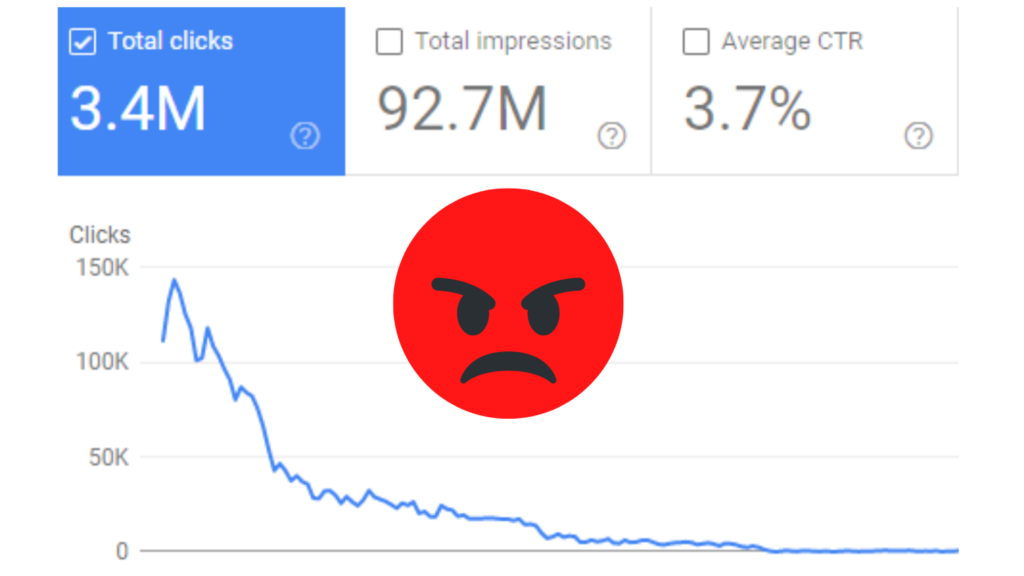
If it was just one page, I wouldn’t be too worried — bugs happen. But take a look at this chart:
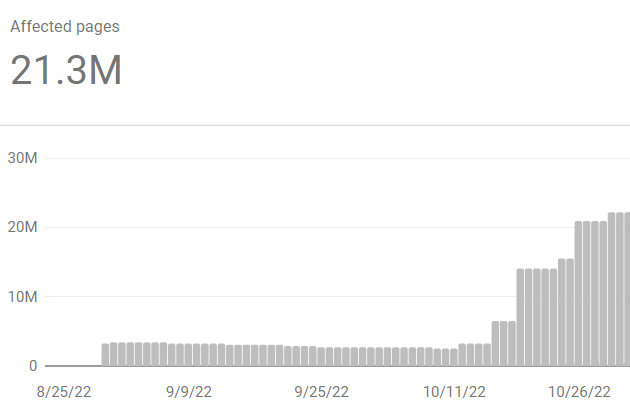
21 million pages were mistakenly marked as duplicates within the last month without any significant structural changes on the client’s end. These pages are now unindexed and don’t bring any traffic to the site. And Google’s shortcomings are costing this business millions of dollars:
At first, I thought this is related to Google’s October spam update, which rolled out on October 19th — coinciding with the sudden increase in the number of “Duplicate, Google chose different canonical than user” pages. But then I found other websites which were similarly affected weeks before that update rolled out. Here are two examples:


Worst of all, in most cases, there’s zero logic to the way Google chooses the canonical variant! The “Duplicate, Google chose different canonical than user” status is fairly common when you fail to differentiate product variants and don’t provide consistent canonical signals.
But in these cases, Google is choosing product A as the canonical page for product B. As in, Google chooses a product page for Samsung Galaxy S20 as the preferred canonical instead of a product page for a JBL speaker! Again, zero logic.
For one of these other websites, Google canonicalized women’s clothing category to… men’s clothing.

We’re not sure what algorithms Google uses for duplicate content detection, but many of them operate on common phrases. For instance, both men’s and women’s category pages contain T-shirts, sportswear, and jeans. But this doesn’t mean they are duplicates. Not even close.
What does this mean?
Google has had similar issues in the past and this might eventually be resolved. But for now, there is no indication from Google that they know about the problem and are working on a solution.
For now, you should remember the following:
- Google may have deindexed URLs on your site thinking they are duplicates, even when they are not.
- Check your Page indexing report in Google Search Console and see if the number of URLs reported as “Duplicate, Google chose a different canonical than user” or “Duplicate without user-selected canonical” recently spiked.
Your next steps are:
- Inspect the pages that you feel are important for your business.
- Find examples when Google chose the wrong canonical.
- Add unique content to let Google see the page has changed.
- Request indexing in Google Search Console.
Know when Google deindexes your pages
We know Google may deindex some pages to free up space for better-quality docs.
We also noticed that Google deindexes many pages during core updates. Ziemek Bućko from Onely wrote an article about this happening after one of the recent updates.
My solution for this is — use ZipTie.
ZipTie can actively monitor if your existing pages remain indexed over time.
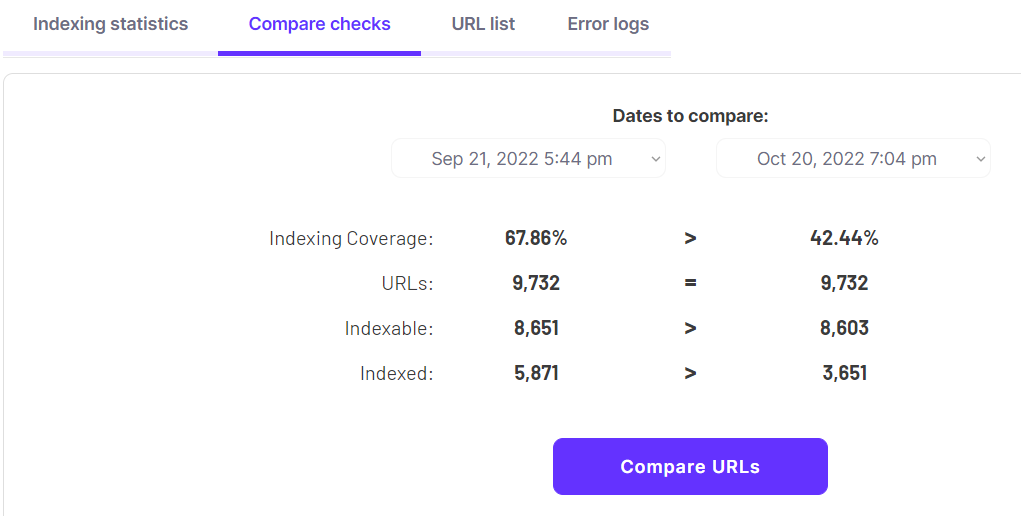
You can easily see which URLs got deindexed by Google.

Then, you can still use Google Search Console to figure out why Google may have deindexed them. But without ZipTie, you risk being surprised by your traffic steadily dropping as your pages are getting deindexed without you even knowing.