Crawled – currently not indexed is one of the most common reasons that a page isn’t indexed. Let’s explore how to fix this issue on your website!
When Google shows “Crawled – currently not indexed” in Search Console, it means Google has seen your page but decided not to include it in search results. This typically happens when Google finds issues with your content quality or technical setup. You can fix this by making your content better, solving any technical problems, and linking to the page from other pages on your site. Tools like Google Search Console and ZipTie.dev can help you track and improve how well Google indexes your pages.
How to check if a page is classified as “Crawled – currently not indexed”
To find affected pages, go to Google Search Console and click on Indexing -> Pages.
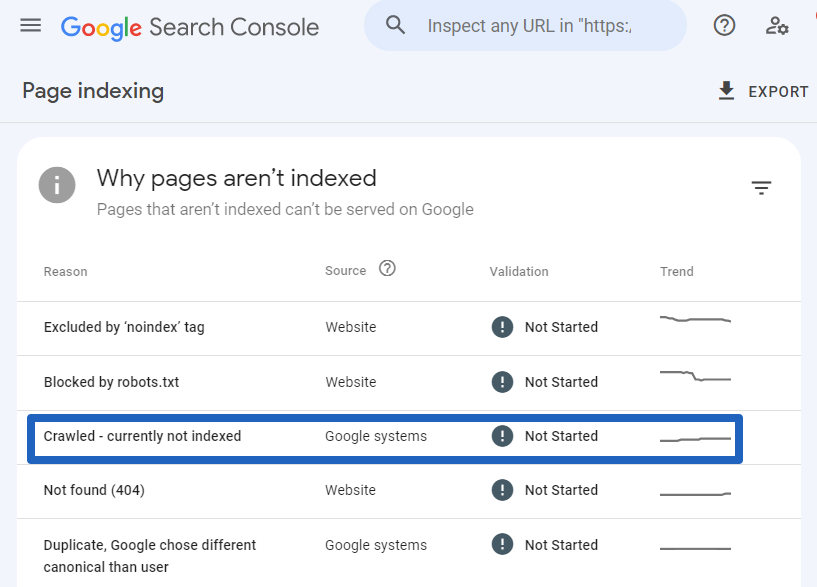
Click on “Crawled – currently not indexed” to see a sample of up to 1,000 URLs.
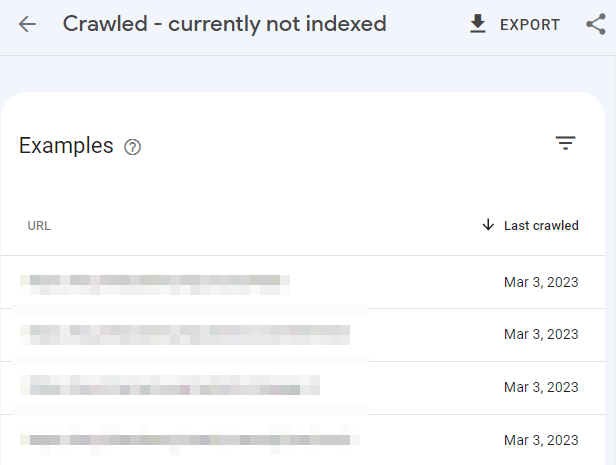
Three most common reasons for “Crawled – Currently not Indexed”
These are the three most common reasons:
- Google considers the page low-quality.
- There are problems caused by JavaScript SEO issues (i.e. Google doesn’t see content generated by JavaScript). Yes, it still happens in 2024!
- The most surprising reason: Google isn’t convinced about the website overall.
Let’s look deeper into these three reasons
Let’s start with the most surprising reason: Google isn’t convinced about the website overall.
It might be surprising, but a page might not be indexed because Google isn’t convinced about the overall quality of the whole website.
Let me quote John Mueller:
- “A lot of the pages that I’ve seen on Twitter that get flagged for kind of these issues where they fall into discovered not indexed or crawled not indexed. It tends to be that the website overall is kind of in this murky area.”
- “A common situation is really that our algorithms are just not sure about the overall quality of the website. And in cases like that, we might crawl the URL, we might look at the content and say: “I don’t know”.”
As ZipTie.dev shows, in the case of Growly.io the vast majority of pages are indexed, so we assume this website is not suffering from quality issues.
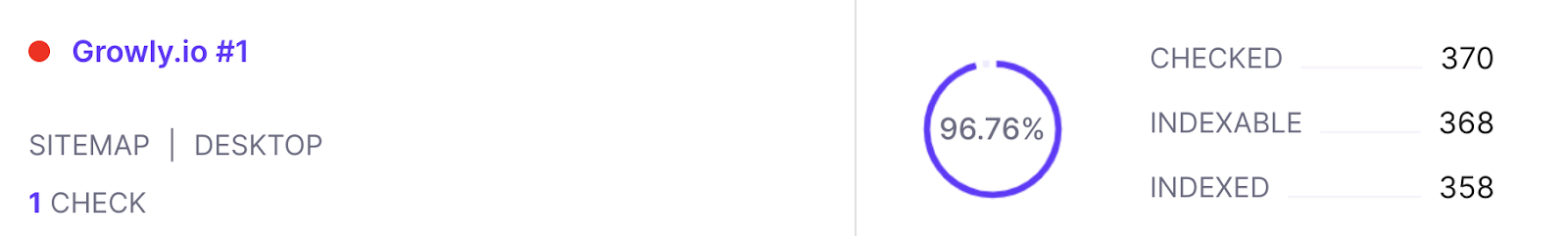
2. Website suffers from JavaScript SEO issues
Sometimes a page might be high quality, but Google can’t see its value because it can’t render the website properly. This could be due to JavaScript SEO issues.
So let’s imagine your main content is generated by JavaScript. If Google cannot render your JavaScript content, then your main content won’t be visible to Google and Google will wrongly(!) judge your pages as low quality.
This can eventually lead to both indexing and ranking problems.
Step 1: Use Ziptie.dev to check JavaScript dependencies
You can use ZipTie to fully check JavaScript dependencies. This way you will see a list of pages with the highest JavaScript dependencies.
Then if you check them in Google Search Console and see they are classified as Crawled Currently not indexed, it’s a sign it may be caused by JavaScript SEO issues.
Let’s take it step by step.
While you create an audit, set an option for JavaScript rendering.
Then you can see the average JS dependency:
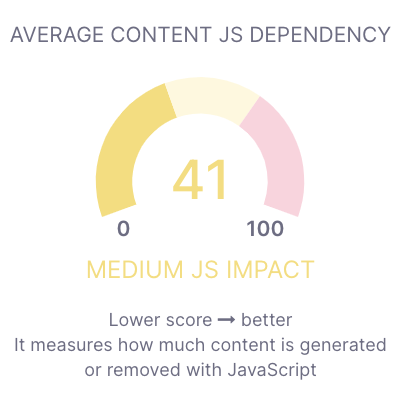
In this case, JavaScript has a medium impact on the website which indicates the website may have indexing problems due to JavaScript.
Then we can navigate to the list pages with the highest JS dependency:
Step 2: Check if Google can properly render your page.
Now we know which elements rely on JavaScript the most. Now it’s time to check if Google can properly render your page.
I explain this in my article: How to Check if Google properly renders your JavaScript content.
3. Reason: A page is unhelpful or low-quality
Google aims to provide users with relevant and high-quality content. If a page is low quality or outdated, it might not be indexed.
To objectively assess your content’s quality, use Google’s list of Content and Quality questions.
What I do quite often is visit the Content Analysis section of ZipTie.dev.
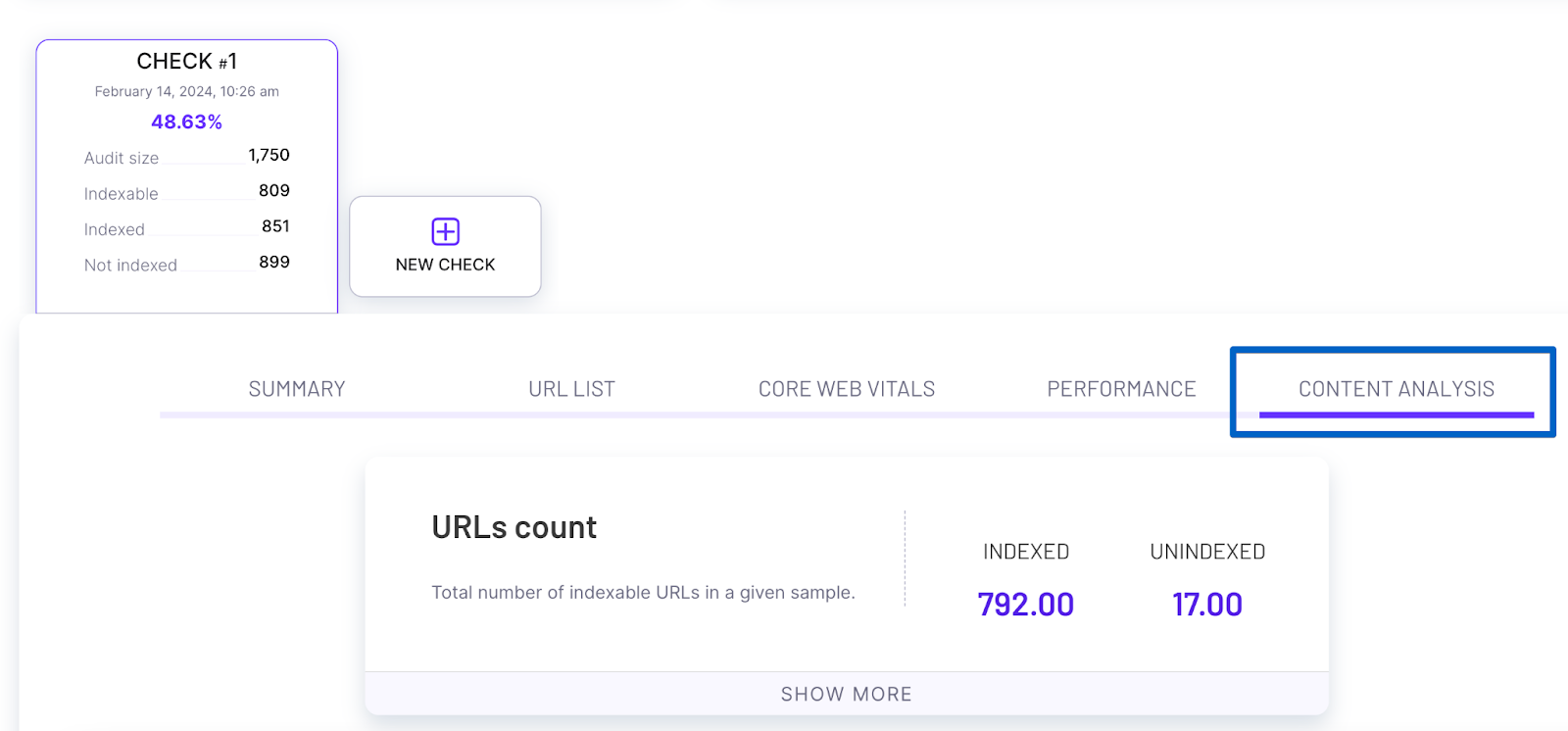
And then I scroll through this report to see the differences between pages that are indexed and pages that are not indexed.
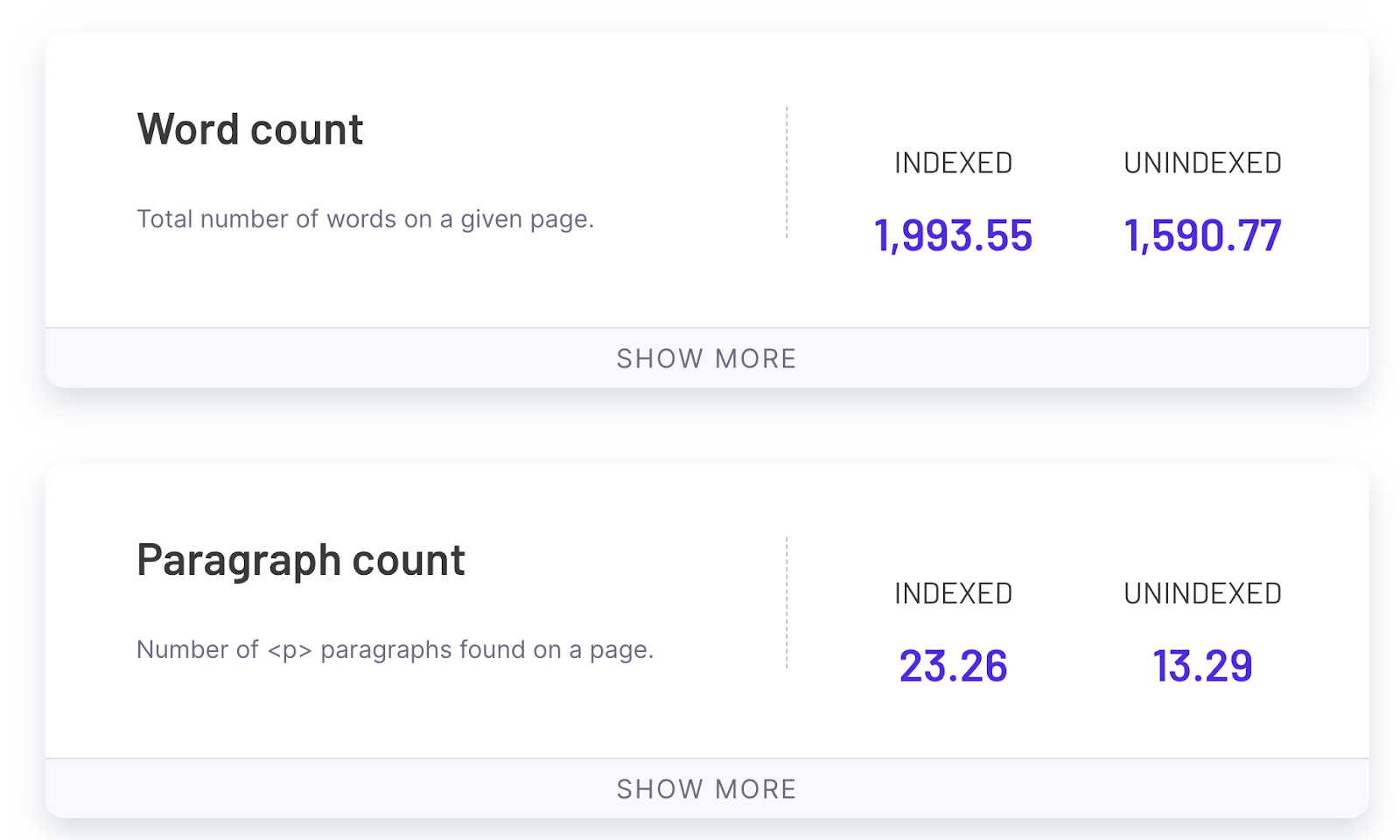
As we can see on the screenshot above, it seems the average number of paragraphs for pages that aren’t indexed is 13 which is 44% lower than in the case of pages that are indexed. We can then formulate the hypothesis that Google is not willing to index pages with lower amounts of content in the case of this website.
Using Ziptie to find patterns of unindexed pages
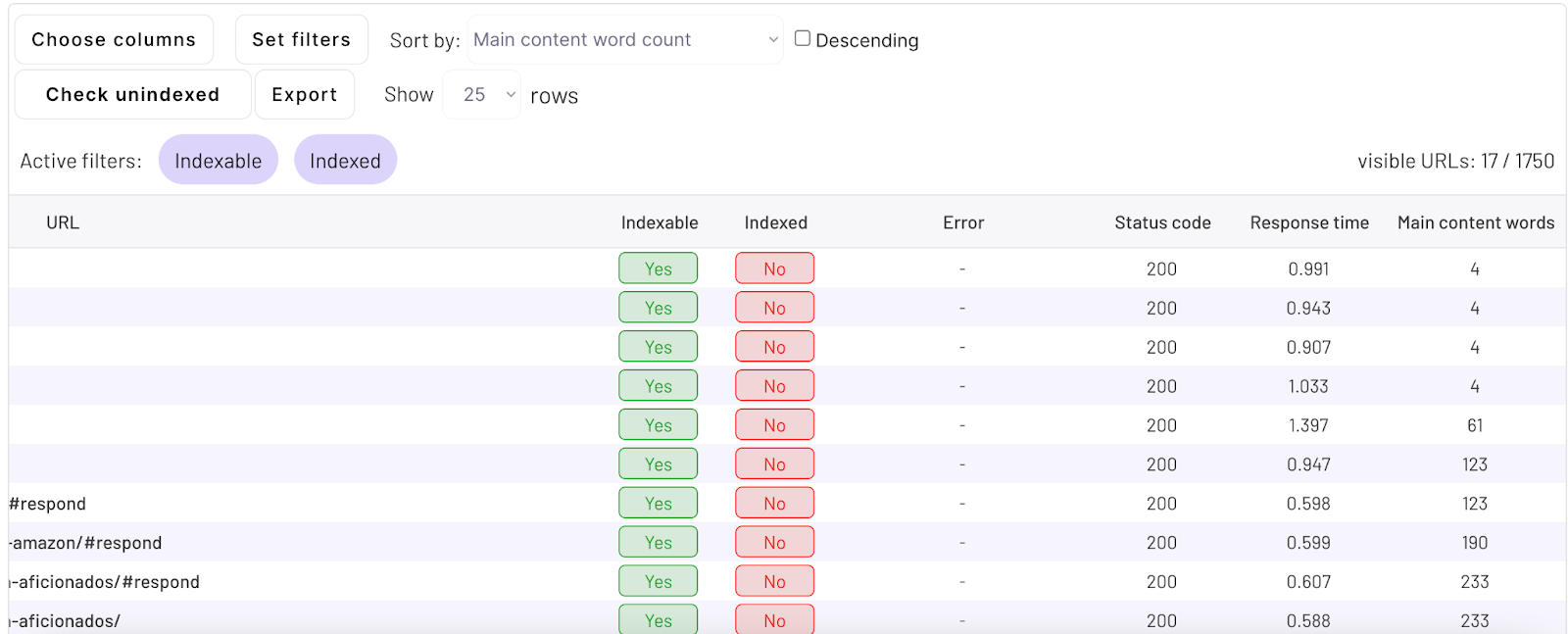
Also, GSC shows limited data – up to 1000 URLs. What I like is to use ZipTie and set filters: “Indexable: yes”; “Indexed: no”.
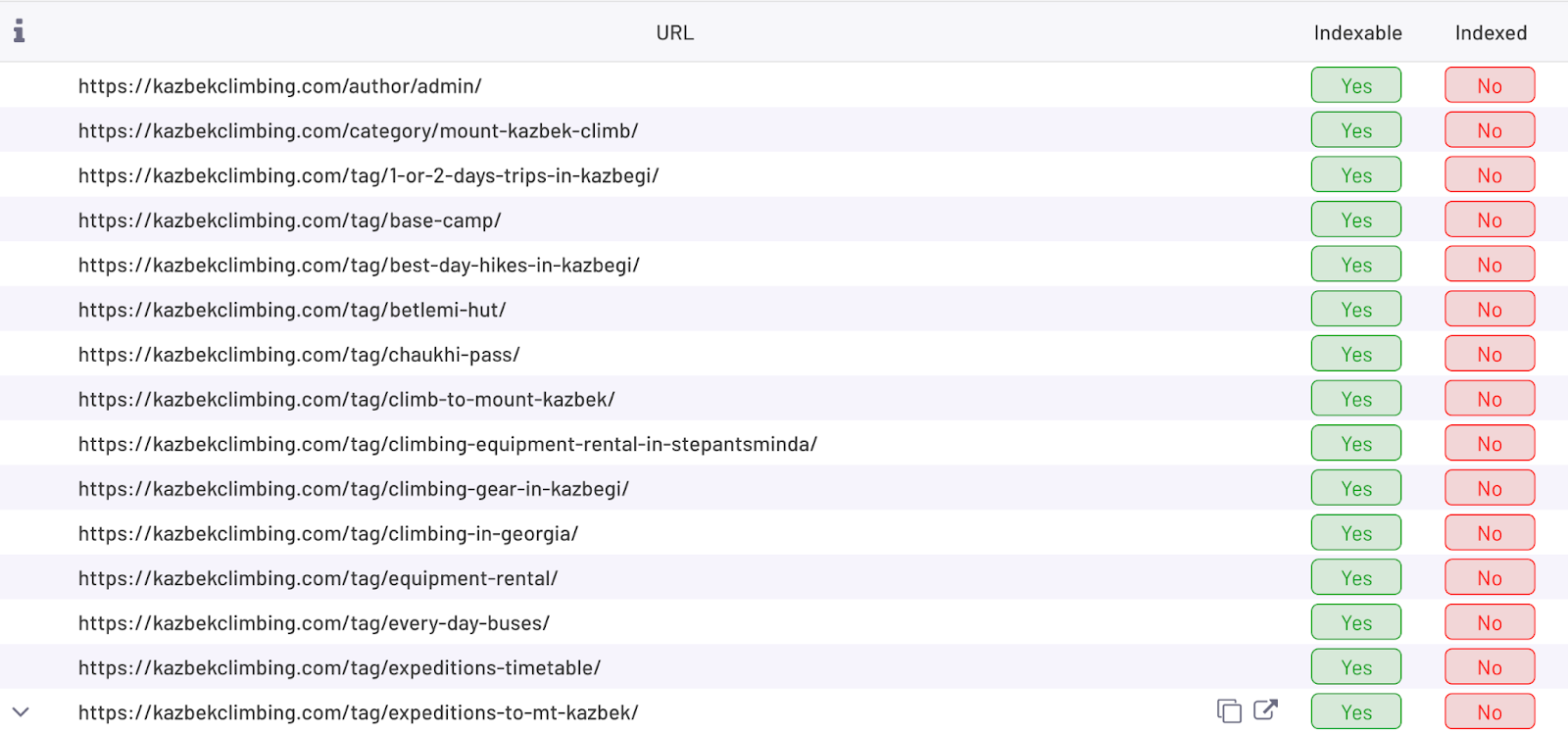
Then I analyze patterns by looking at the URLs. As we can see on the screenshot below what tends to be not indexed is:
- Author pages
- Category pages
- Tag pages
Another option is to sort by main content word count. Pages with the lowest number of main content words are likely to be not indexed in Google (Google is not willing to index pages with little to no content).
If you want to make them indexed, follow the workflow I present in the latter part of the article.
The two-step workflow to fix “Crawled – Currently not Indexed”.
At a glance, the workflow to fix “Crawled – but not Indexed” is very easy:
- Identify the reason why the page isn’t indexed (e.g., low-quality content, JavaScript issues, or website quality). To perform this step, I use a mix of Ziptie and Google Search Console.
- Address the specific issue (e.g., improve the content, fix JavaScript problems, or enhance overall website quality).
All the steps are presented on the diagram below:
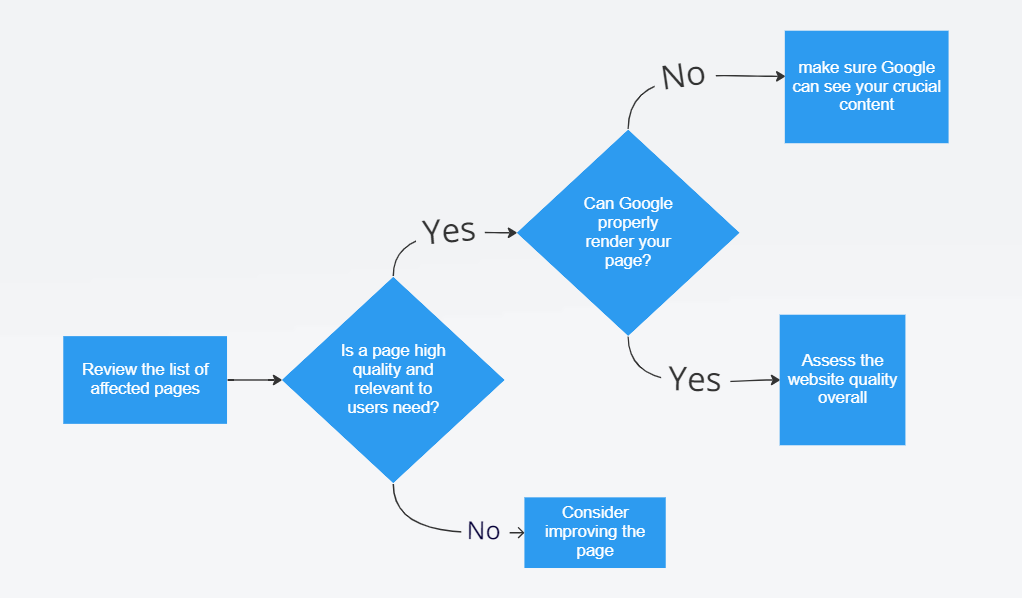
First, you need to check if your content is good enough and if there are any technical problems. Make your content better by adding unique, helpful information. Also check if JavaScript is causing any issues. Once you’ve made these fixes, go to Google Search Console and ask Google to index your page.
Take control of your deindexed pages
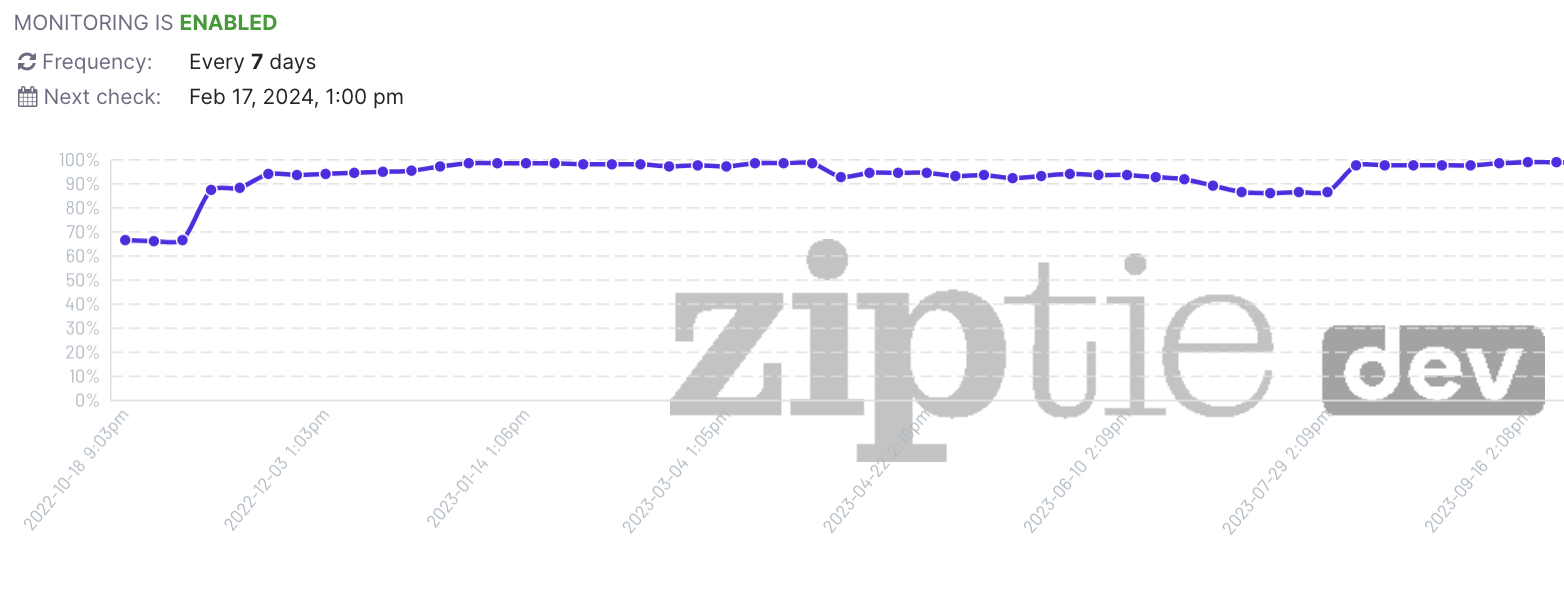
In this article, I explained that one of the reasons for the status “Crawled – but not Indexed” is when a previously indexed page gets removed from the index. This occurrence is quite common, particularly during core updates.
Luckily, ZipTie.dev provides an Indexing Monitoring module that can help you with this. By using ZipTie, you can easily identify the specific URLs that have been deindexed by Google.
Don’t hesitate to give it a try and see the benefits for yourself! Check out our 14-day trial FREE OF CHARGE.