Google doesn’t index all content on the internet. With limited resources and an ever-growing amount of online content, Googlebot can only crawl and index a small fraction of it.
To quote Google’s blog: “Google has a finite number of resources, so when faced with the nearly-infinite quantity of content that’s available online, Googlebot is only able to find and crawl a percentage of that content. Then, of the content we’ve crawled, we’re only able to index a portion.”

This challenge has grown more significant over time, making indexing even more difficult today, when many businesses generate content using artificial intelligence and Google needs to be more selective about which pages will end up in the Google’s index.
Let’s learn why and how to stay on top of this.
For 2023 Google needs a machete, not a scalpel
As more website owners use artificial intelligence (AI) to create content, the quality of AI-generated content becomes a concern. Google needs to build more sophisticated algorithms to detect low-quality content, regardless of the source.
The stake is high.
If Google is not successful at filtering low-quality AI-generated content, it will massively reduce the quality of its search results. It’s easy to foresee the implications: Google may lose lots of users, and suffer decreased revenue.
All websites can be affected
Personally, I expect this to have a massive impact not only on those websites heavily reliant on Artificial Intelligence but all websites with content that could be treated as borderline.
It’s happening now.
Website-quality score matters
Sometimes, a page isn’t indexed not because of its content but due to a sitewide issue. Google might not see the overall website, or even a part of it, as worth indexing. Improving the overall quality of your website can help with indexing.
Here is confirmation from Google’s John Mueller:
“Usually when I see questions like this where it’s like, we have a bunch of articles and suddenly they’re not being indexed as much as they used to be, it’s generally less of a technical issue, and more of a quality issue. (…) It’s more a matter of just our algorithms looking at that part of the website, or the website overall, and saying, we don’t know if it actually makes that much sense for us to index so many pages here. Maybe it’s OK if we just index a smaller part of the website instead.”
Slow website ~ problems with indexing
But even if your website is of a high quality, it may end up having problems with indexing if servers can’t handle Googlebot’s request.
As pointed out in Google’s Gary Illyes’ article, “Google wants to be a good citizen of the web”. So it doesn’t want to bother your servers too much.
The rule is simple.
- Your website is fast -> Google can crawl & index more.
- Your website is slow -> Google crawls & indexes less.
The diagram below coming from one of our clients is a perfect illustration of the problem.
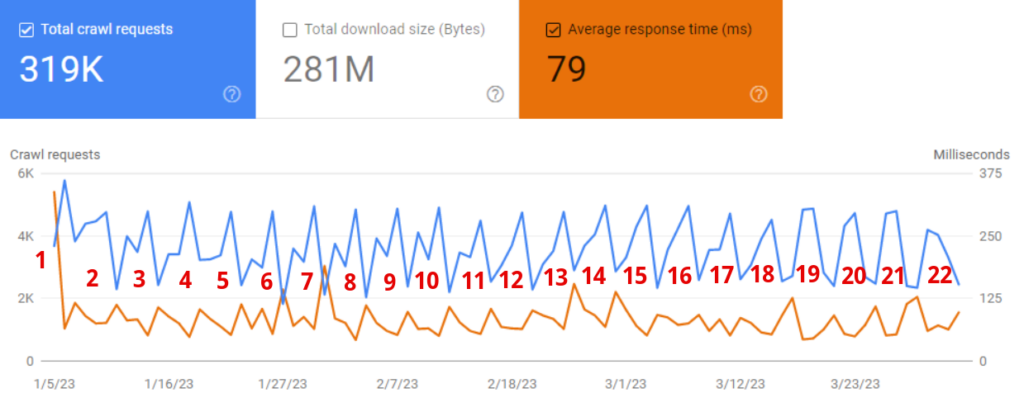
Just look what happens when the average response time goes down (orange line). At the same time, the total number of requests goes up.
Commonly slow servers lead to massive problems with pages classified as “Discovered – currently not indexed”.
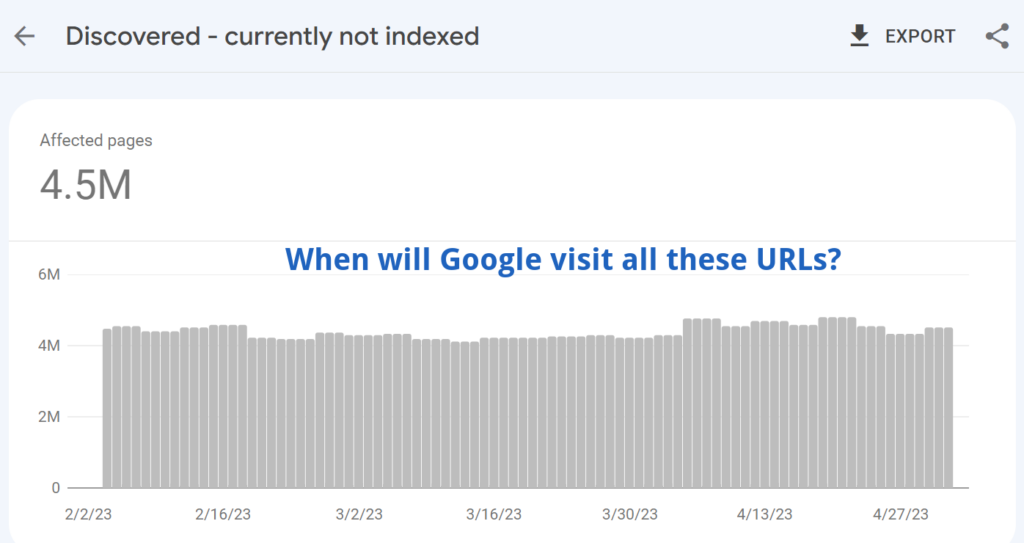
Important note: Speed is not just about server performance but also overall website performance. Here is the proof – slow rendering means slow indexing.
Why does Google need to keep its index lean?
Problems with indexing are not only caused by low-quality content issues.
Let me explain why Google has to keep its index lean.
Indexing is costly for Google
Indexing is expensive for Google as it requires rendering pages and using complex algorithms like MUM and BERT. As a result, Google is cautious about deciding which URLs to include in its index.
According to Google, rendering alone takes 20x more resources.

With extremely costly algorithms such as MUM or BERT, we cannot estimate the real cost.
It’s worth mentioning what Google once said that “Some of the models we can build with BERT are so complex that they push the limits of what we can do using traditional hardware”. Consider the fact that BERT is used for every user query and MUM is even more costly.
Oversimplified calculation: Google’s indexing cost is now over 40x more than just a few years ago.
This is why Google thinks twice about whether a given URL should be included in Google’s index.
Users need results fast
Users want quick search results, so Google must maintain a lean index to avoid longer wait times.
Let’s imagine that the size of Google’s index has doubled. All things being equal, it could take much longer for users to find results.
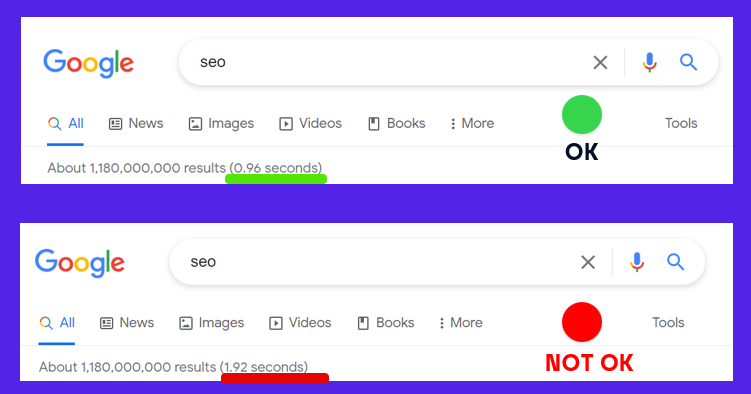
This is why Google needs to keep its index lean and be selective about which pages get indexed.
Indexing is often temporary
Even if Google indexes a page, there’s no guarantee it will remain indexed forever. When data centers are too busy, some content may be deindexed.

Here are just two examples of two core updates that occurred in the last few months that had a massive impact on indexing.
- Google’s spam detection became more aggressive. As we can see in Google’s statement, “In 2021, SpamBrain identified nearly six times more spam sites than in 2020”. As I wrote in my other article about Spam Update, we noticed that Google deindexed a lot of pages around Google’s spam update (19th October 2022).
- Google’s duplicate detection algorithms are stricter.
I expect that future core updates will cause massive deindexation across various niches, in particular: e-commerce stores, classifieds, and marketplaces. More website owners can expect a rising number of pages classified as:
- Crawled – currently not indexed
- Soft 404
How do I deal with the problem of Google deindexing your content?
- When Google deindexes your content, I recommend identifying which URLs were deindexed. It can be challenging to determine which URLs have been removed from Google’s index, as Google Search Console doesn’t provide a specific report for that. However, you’re in luck! ZipTie offers a monitoring feature that makes it easy for you to identify the URLs that have been deindexed by Google. Give it a try and see for yourself!
- Once you have identified which URLs were deindexed, you can classify which ones are important to you.
- You can then work on improving the quality of your content.
- Then, reindex to make it work.
This process is beneficial for two reasons:
- Improving content increases the probability the page will be successfully reindexed.
- Improving content can have a positive impact on ranking.
Wrapping up
To sum up, we can see that Google cannot afford to index all pages.
Google is forced to cut some pages from the index because:
- The rise of AI creates a huge number of low-quality content.
- Google’s content quality control is more and more demanding.
- Indexing is extremely costly in the long run (considering all the content algorithms being used). That’s why Google wants to keep its index lean.
- Slow websites can have a negative impact on indexing.
How ZipTie can help?
If you suffer from indexing issues, check out ZipTie.dev! We have plenty of tools to handle your indexing issues. Try us out for free with a 14-day trial!