“Discovered – Currently not indexed” is a common indexing issue in Google Search Console. It means Google knows your page exists, but hasn’t visited it yet.
This article explains why this happens and provides solutions.
Four reasons for “Discovered – currently not indexed”
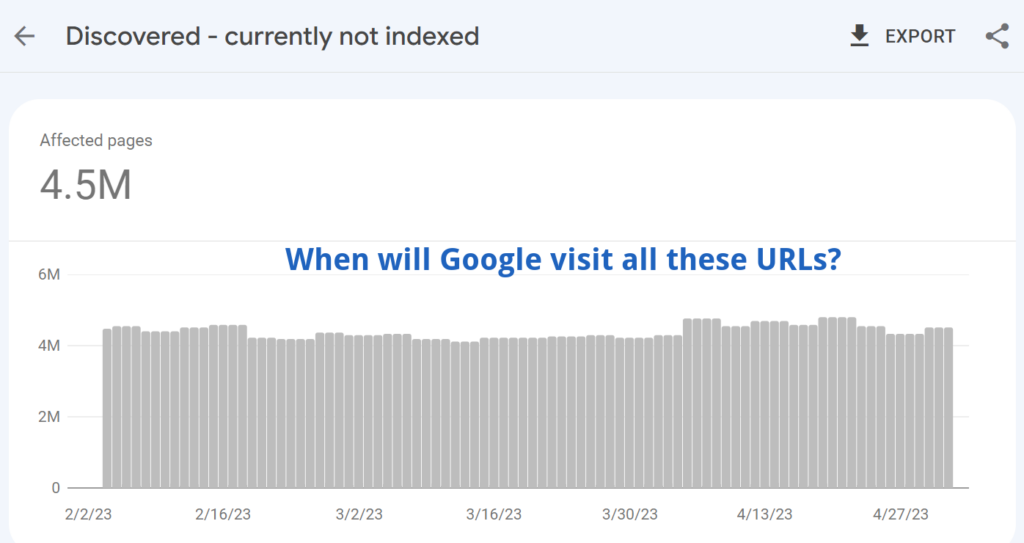
There are four reasons for “Discovered – currently not indexed”:
- Your website is slow and Google limits crawling to avoid overloading your servers.
- The page is very new so Google hasn’t had a chance to visit and index it yet. Google may crawl and index it soon.
- Your entire website is not a priority for Google
- One page of your website is not a priority for Google
Let’s explore the reasons and solutions for this problem.
Reason: your website is slow
Google tries to limit crawling on slow websites to avoid overloading servers.

As a result, many pages can be classified as: “Discovered – currently not indexed”.
Why does this happen? As Google’s Webmaster Trends Analyst, Gary Illyes, pointed out, Google aims to be a “good citizen of the web.” Faster websites allow for more crawling and indexing.
The rule is simple:
- Your website is fast -> Google can crawl and index more.
- Your website is slow -> Google crawls and indexes less.
How to analyze website performance
To analyze Performance we recommend using ZipTie.dev. As you can see on the screenshot below, this website has massive problems with performance – many parameters including response time are very weak, much worse than other websites in our database.
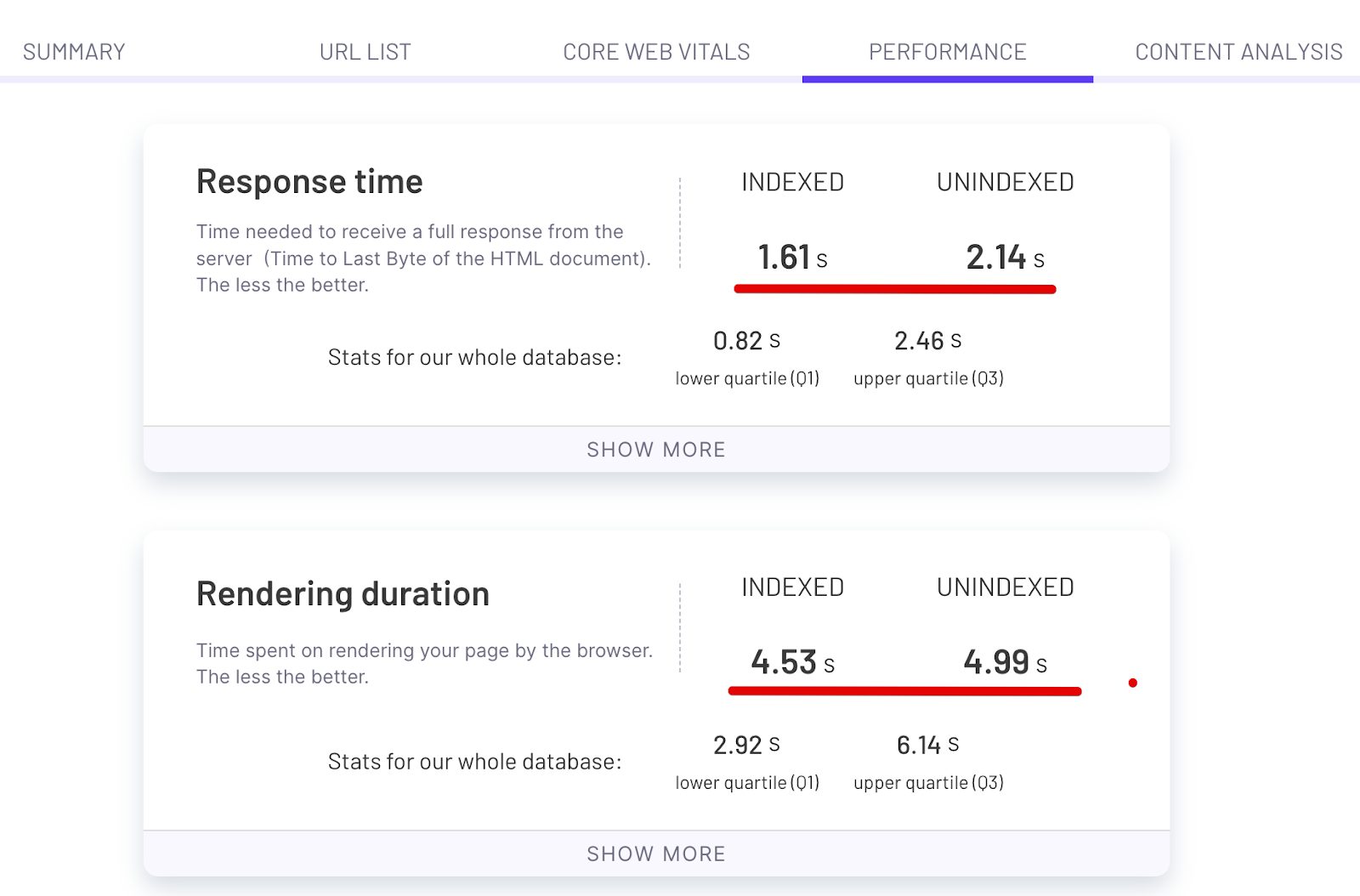
This is something that can negatively affect indexing. As a result, Google may classify many pages as “Discovered – currently not indexed”.
Google’s documentation is wrong
Google’s Page Indexing Report documentation illustrates that the typical cause of the “Discovered – currently not indexed” message is due to Google not wanting to overload the site.
Based on my observation, this is extremely inaccurate. In fact, it’s just one of many factors.
On many occasions, I’ve seen websites with fast servers that were still struggling with the “Discovered – currently not indexed errors.
Why? Because either crawl demand was extremely low, or Google was busy crawling other pages.
Reason: your entire website is not a priority for Google
Your website competes with the entire internet for Googlebot’s attention. This applies to both new and established websites. For new websites, Google needs time to collect signals about your site. However, even well-established websites can struggle with crawl demand.
Which signals make Google crawl more? Google is not willing to release the details of its secret sauce. However, based on public information provided by Google, we can compile the following list of signals:
- website popularity
- website quality
- website relevance
- website uniqueness
- update frequency
So you should find a way to optimize your website for these signals.
Reason: your PAGE is not a priority for Google
It may also be the case that while the crawl budget for your overall website is high, Google might choose not to crawl specific pages due to either a lack of link signals, predictions of low quality, or because of duplicate content.
Further explanations for each of these causes are provided below:
- A page lacks the required signals to convince Google that it is important, for instance, if there are no links pointing to the page.
- Google’s algorithms predict that a page won’t be helpful for users. I.e., it falls under the pattern of low-quality pages causing Google to reject visiting it.
- A page is a duplicate. Google recognizes patterns of duplicative URLs and tries to avoid crawling and indexing that type of content. As Google’s Search Advocate, John Mueller stated: ” […] if we’ve discovered a lot of these duplicate URLs, we might think we don’t actually need to crawl all of these duplicates because we have some variation of this page already in there”
What you should do
Step 1: Assess the Severity
The first priority is to check if the problem with “Discovered – currently not indexed” is severe.
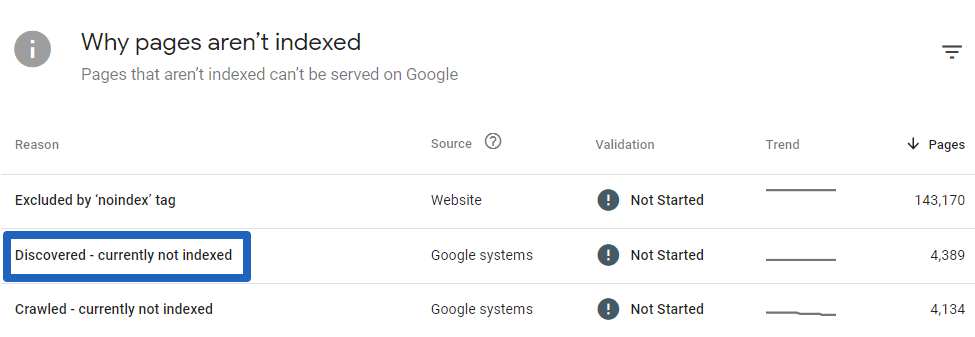
Go to Search Console and Indexing -> Pages and then scroll down to the Why pages aren’t indexed” section. Then check how many pages are affected. Is it just a small percentage of your website, or a massive part of it?
Step 2: Review Affected Pages
Then review a sample of affected pages. You can do this by clicking on “Discovered – currently not indexed”.
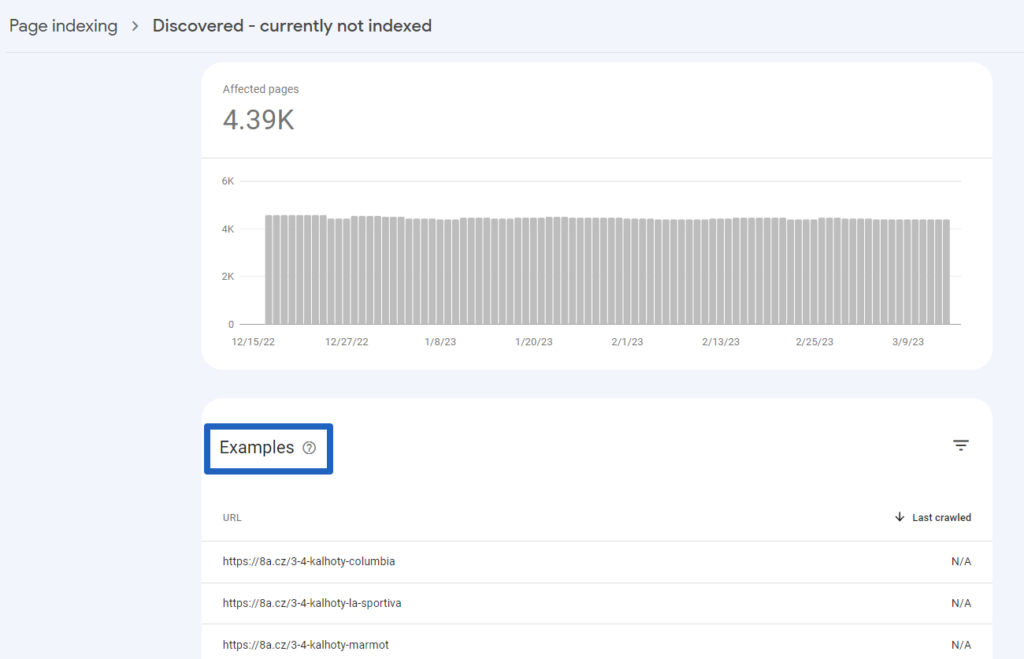
If there are just a few important pages classified as “Discovered – currently not indexed”, make sure that there are internal links pointing to them, as well as whether these pages are included in sitemaps. This easy fix should work in most cases.
Step 3: Address the Issue Thoroughly
If there are many important pages classified as “Discovered – currently not indexed” that means the issue is broader. Here’s your action plan:
- Ensure your server is healthy.
- Focus on improving your website’s quality. Enhance the existing content and ensure that Google indexes only high-quality content. As explained in The Hidden Risk of Low-Quality Content, Google assesses quality based on indexed pages. To maintain a good reputation, only allow the indexing of high-quality content.
- Review your crawl budget. Make sure Google isn’t wasting resources on crawling low-quality pages.
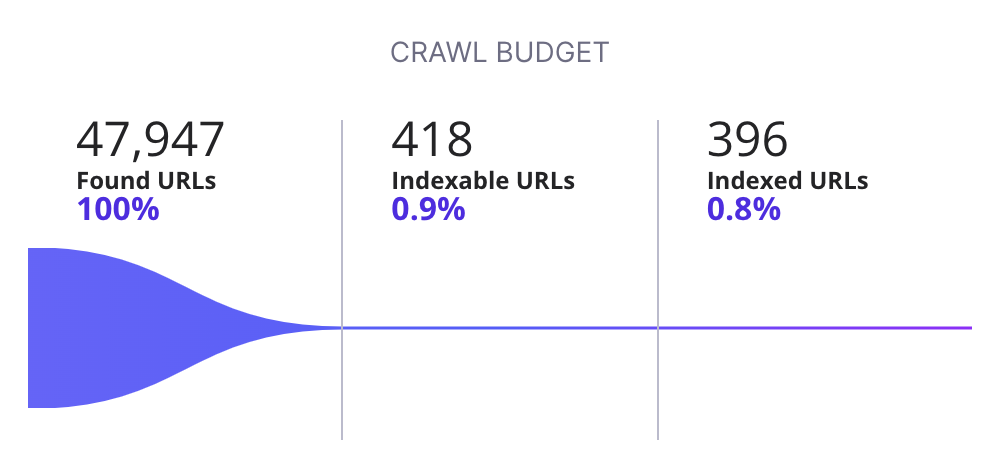
How to analyze the crawl budget using ZipTie.dev?
To analyze your crawl budget you can use ZipTie.dev. In this case just 1% of URLs are indexable, meaning 99% of URLs Google can visit are not intended for indexing. It’s a total waste of crawl budget: as for every 1 indexable URL, Google has to visit 99 non-indexable URLs.
- Show Google that a page is important by creating internal links that point to the page.
FAQ
What is “Discovered Currently Not Indexed”?
“Discovered Currently Not Indexed” means Google knows about your page (through sitemaps or internal links) but hasn’t added it to its search index. This is different from not being crawled – the page may have been crawled but Google decided not to index it.
What causes pages to be “Discovered Currently Not Indexed”?
Common causes include low-quality or duplicate content that Google chooses not to index, limited crawl priority for new or less authoritative sites, technical issues preventing proper indexing, and content that doesn’t meet Google’s quality thresholds.
How can I check which pages are affected?
In Google Search Console, go to “Pages” under “Index” section, then find “Discovered – currently not indexed” under “Why pages aren’t indexed”. This shows all affected URLs.
Why isn’t Google indexing my important pages?
Google might not index pages if they’re similar to existing indexed content, the content quality is deemed insufficient, technical issues make indexing difficult, or the site’s overall authority is still developing.
How can I fix this issue?
Focus on these key areas: improve unique, high-quality content, ensure proper technical setup (clean URLs, proper internal linking), build site authority through quality backlinks, remove or fix low-quality and duplicate content, and use tools like Google PageSpeed Insights to check technical health.
When should I be concerned?
Be concerned if many important pages remain unindexed, the issue persists for several weeks, your competitors’ similar content is being indexed, or you’re losing traffic due to non-indexed pages.
Wrapping up
By following these steps, you can address the “Discovered – Currently not indexed” issue in Google Search Console and improve your website’s visibility in the search results. Keep monitoring your website’s performance in the Search Console and make necessary adjustments to maintain optimal visibility.